
读文献和记笔记是很个人的事,所以我的分享更多是抛砖引玉,以英文PDF文献为主,希望大家轻拍  .
.
首先,文献的采集和管理是重中之重,我主观上更偏向Zotero,相比于其他的科研管理工具比如Mendeley,endnote,Citavi, papers等等,它开源免费,文章导入和元数据提取方便准确,专注于管理而没有多余的功能,还有跨平台和丰富的插件(有了插件的zotero跟没有插件的zotero不是一个软件),很适合作为笔记软件和Latex,word写作的胶水. 关于Zotero和Logseq的联动可以参考https://cn.logseq.com/t/topic/121.
Logseq用来做学术笔记,简单来说就是三个目的:
(1) 输入: 读书籍和paper,理解消化并将读过的内容通过双链与正在读的内容串联起来;
(2) 内化: 记录自己的学术灵感,并与读过的内容串联起来,碰撞出新的火花;
(3) 回顾: 每日和随机的方式提醒自己哪些文章没有读,哪些文章的知识点还没有理解,哪些知识点值得回顾和温习.
这篇分享主要是说第一点如何读论文,写Literature notes on logseq.
-
整体结构
1.1 Research ideas
- 平时记笔记的最小单位,相当于fleeting notes,里面是你随时灵感迸发就随手记下的,或在读文章时启发出来的,都可以加这个标签;
- 自底向上的逻辑,如同盒子里的小卡片,足够多的积累就会形成足够多的灵感.所以层级不重要,标签更重要,添加适度的tags会让未来信息汇集更方便;
- 请在内容里尽量少地添加标签之外的双链,因为此时的想法都是比较原始无序的,不能称之为知识,也许有些东西还要推倒重来或者丢进垃圾箱,需要你未来整理完善的过程中在permanent notes里面慢慢与已有的知识进行融合.

1.2 permanent notes
-
你的知识的结晶,以一个知识点为最小单位,原子化;也可以叫evergreen note
-
是一种自顶向下的逻辑,个人比较建议每隔一段时间进行主题和层级分类,理清各个知识点的关系;
-
跟其他tags充分链接
-
以后如果有插件了,可以制作anki card供自己温习 (spaced repetition).

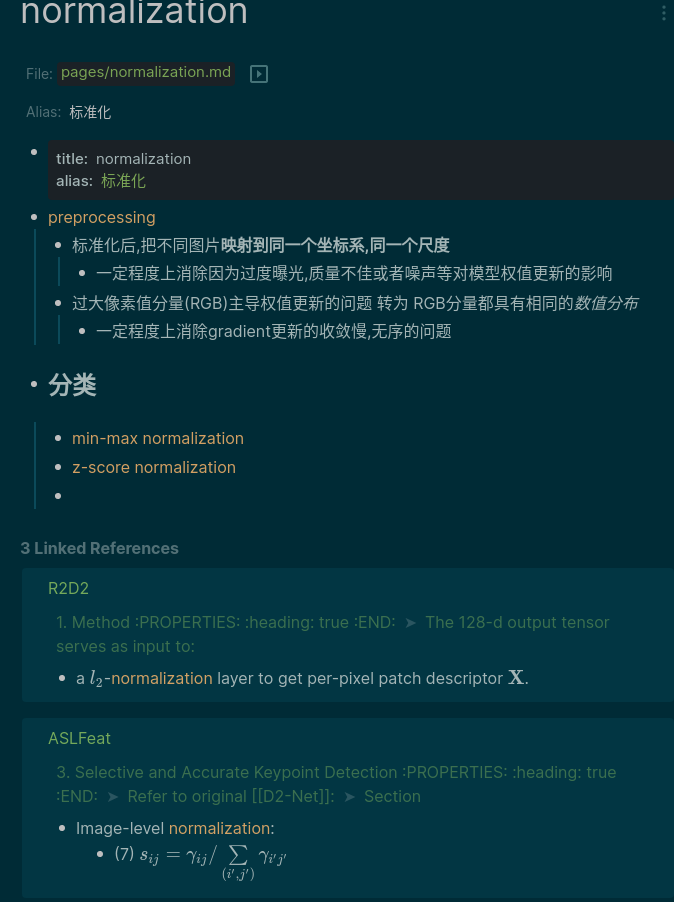
1.3 literature notes
- 学术笔记,以一篇文章为最小单位;
- 文章在读的过程中不断丰富标签
- 下面第2,3章节重点讲解它的使用方法
1.4 Projects
- 以一个主题为中心,以输出文章为目的,若干permanent notes的集合
- 一种主动学习的方法,比如想要写一篇文章或者做一个presentation,那么就把这作为project,围绕这个project搜寻文献,建立fleeting notes和literature notes
- 用todo, done, priority等管理项目
- literature note模板
这是我的个人模板

(a) Meta Data - 文章的元数据,包含作者,年份,出版信息
(b) Introduction - 用简洁的语言介绍一下动机和问题描述
(c ) Strucutre - 系统流程图或者算法框架图拆解,宏观梳理逻辑关系
(d) Method - 方法描述,也就是记笔记的核心
(e) Writing skills - 如果这篇文章里面有些表达句式和词汇让你觉得很惊艳,或者一些固定搭配你经常在别的文章中看到,就可以放进这里
- 文章的导入和元数据提取
碰到一篇论文,首先导入到Zotero中,然后简单读一下摘要,根据摘要对其定位.在侧边栏中编辑标签,把你认为这篇文章所属的主题(比如computer vision),用到的方法(比如DLA)做成关键词加进去,甚至你可以加一些文章的"特色",比如这篇文章专注于"efficient".
接着将文章通过mdnotes导出到一个md文件中,再复制粘贴到你新建的logseq page中. 这个page的标题看你的喜好,比如你可以用文章里提出的模型方法的缩写,也可以用文章全名,也可以用年份+作者+文章之类的. 我随便拿一篇文章举例,导入后的效果如下左图所示:


读了摘要,把它拆解精简成能很好理解的outlined的形式,如上右图所示,作为非英语母语人士,尽量把一些小标题,连词和一些关键动词用中文,专有名词用英文,数字用阿拉伯数字,这样可迅速抓住重点不会迷失.
- 同时别忘了给页面初步加上标签#toread, #精度(跳读)这类的状态标签
- 笔记的输入
首先我们要确立这样的一个共识,就是一篇文章主体章节70%~80%都是旧知识,而这些旧知识中根据个人水平的不同又分为你已经知道的知识点和你没听过或一知半解的内容.
所以个人建议在第一遍粗读文章的时候快速浏览每个小章节讲的是什么,并用记号笔把一些觉得有用有趣的地方高亮,有疑问的地方打上问号,力争从整体上把握这篇文章的脉络和思路,并敲定是否值得你精度,是否需要补充一些标签.
接着在精读文章"从厚变薄"的过程中要不断地向自己提问,这个概念/方法是不是在别的书上paper上看过(打开搜索搜一下关键词,如果有,通过侧边栏打开作为参考并针对这篇文章进行完善; 如果没有,就新建一个页面并为其添加分类标签),为什么这个矢量不在欧几里德空间?为什么最后要归一化?等一下,归一化和标准化又有啥区别? 反正做一个杠精吧!
如果这些问题文章里面有回答了,那么就在问题底下直接写上答案,并在涉及的permanent note里面进行更新完善;如果文章没有回答,就把它放进questions的标签; 如果这个问题给了你一些启发,那么放进research ideas的标签; 如果你发现这个地方跟某篇文章讲得很相似,你可以通过block引用或嵌入的方式将那篇文章相关信息链接过来,既减少重复工作,又能让你把新旧知识串联起来.
- 非常重要的一点是尽量不要把文章里的话复制粘贴过来,而是用自己的语言理解并用简短的语言复述
- 复述的过程中通过outline的分层按照总分的关系拆解开,保证每个block的原子化
- 用中文作为逻辑连接词和着重提醒词,比如"但是",“重要”, 英文作为主体, (英文非常好的同学可以无视这段话)
- 当然在整理内化为permanent note的时候根据自己的需要可以全部转成英文(方便自己直接输出为论文),也可以保留中英文混用(方便自己随时阅读)
- 读完之后记住更新阅读状态: #readdone 评分:#5
 .
.
- 自定义标签
-
permanent note根据学科的不同自定义你的学术标签,比如理工科的同学可以用
concept, definition, theorem, lemma, 模型,网络,工具,优化方法, 等等这类标签 -
literature note在此基础上还要定义状态标签,除了上述提到的toread/reading/readdone,还可以加评分3
4之类的; -
同理project里面可以添加towrite/writing/writedone,并加入deadline, schedule.
-
别名也非常重要,我主要用别名来管理:
(1) 同义词, 比如happy, delighted (2) 缩写, CNN <-> Convolutional Neural Network
(3) 相似概念,比如inner product, scalar multiplication (4) 词性变化, supervision, supervised
(5) 中英文翻译
标签的数量不要太多太杂,因为你会记不住,而且过多的链接会让图谱过于复杂反而失去了意义.标签之间不要有太多重叠,尽量低耦合,来体现不同的方面.
个人建议重要的知识点一般要有至少一个常用标签(questions, research ideas, permanent note等)和至少一个主题标签,这样它就不会永远地丢失在你的笔记当中,你可以通过在daily note中加入query将其唤醒.