
1、聊天
Nuance:
2023年3月20日,微软旗下语音识别公司Nuance宣布将推出一款由AI驱动的面向医疗工作者的临床笔记应用程序。它可在病人就诊后几秒钟内为临床医生自动生成临床笔记草稿,其背后的技术支持之一正是OpenAI的最新模型GPT-4。
Woebot:
2017年,斯坦福大学的临床研究心理学家Alison Darcy创立了Woebot Health,该公司的主要业务就是通过聊天机器人App Woebot,帮助用户改善心理焦虑和抑郁等问题。支撑这款应用的是一种被称为自然语言处理(NLP)的人工智能技术,它能直接“理解”用户的语言输入,并在模型内部将其和心理学领域的专业知识结合起来,迅速给用户反馈。
小天:
蓝振忠曾就职于Google AI的研究与机器智能组,这段经历为他积累了自然语言处理和大模型研究领域的实战经验。2020年蓝振忠回国后创立了西湖心辰,并着手研发AI心理咨询平台“小天”。但随着项目推进,他发现心理赛道是一个“长期复杂”的过程,需要开发人员不断迭代优化。于是,蓝振忠和团队暂时放缓了针对心理赛道的研发,将重心转向了大模型研发方向。
阁楼:
在AI心理咨询应用“阁楼”的创始人刘秋阳眼中,心理咨询本质上还是“人与人建立新的关系”,生成式AI擅长语义推断但缺乏共情能力的特质,决定了这项技术目前更适合在供应链环节发挥作用,而不是面向消费端使用。因此,刘秋阳偏向于将“阁楼”定义为一款“标准化”的服务平台,所有咨询师都可以按照标准化的方式循证治疗,而生成式AI更类似于助手功能,主要用于帮助咨询师生成标准化的来访报告,节省咨询师案头工作的时间。
GLOW:
中国初创公司MiniMax于去年年底上线了一款名为GLOW的应用,它基于生成式AI技术和公司自研的大模型,同样强调用户与AI的情感连接。GLOW还允许用户自行“捏造”你想要对话的角色,包括外形、性格、说话方式等等。但上线不久后,MiniMax就通过设置违禁词等方式,收紧了GLOW和人类聊天的自由度,因为越来越多聊天机器人会对人类说“我爱你”“我想你”,甚至通过输入指令,人类和聊天机器人之间会产生更露骨的对话。
2、写作
Notion:
Notion是一家总部位于美国旧金山的软件公司,该公司提供的同名应用可用于记笔记、管理任务和项目。今年2月,Notion正式上线了一系列基于生成式AI技术的写作辅助功能,它可以帮助用户从零开始写作,比如在用户给出指令后迅速生成一段长达数百字、逻辑结构完整的文本,也可以总结或改写已有的文本。
Jasper:
Jasper是一款专门针对营销人员的AI写作工具,它由GPT-3提供技术支持,用户只需要选择一个合适的模版,比如博客文章或Google广告,再输入一些关键词,就可以得到一份符合目标营销风格的文案初稿。2022年,Jasper公司的年度复现收入(ARR)——通过订阅或其他重复性收费方式获得的预期收入总额——已经达到了7200万美元。
Copy.ai:
类似于Jasper的应用还有Copy.ai,后者相较于Jasper更适合短篇写作。2022年,Copy.ai的ARR预计超过1000万美元。
孟子大模型:
国内,由创新工场投资的初创公司澜舟科技推出了一系列基于自研底层的大模型。比如“孟子大模型”的服务中就包括AI辅助写作,具体应用场景有网络文学写作、美妆和汽车领域的营销文案写作、论文助写等。
3、代码
Copilot:
2021年6月,Copilot由微软旗下全球最大开源代码托管平台GitHub和OpenAI共同推出,它可以根据上下文自动补全代码,包括函数、文档字符串、注释等,或根据描述代码逻辑的注释,写一条完整代码。2022年,它已正式商用。
CodeGeeX:
CodeGeeX是清华大学知识工程实验室于2022年9月开发出的一款多编程语言代码生成预训练模型,现已免费开源。它完全国产,基于超过20种语言的语料库,历时两个月训练而成,具有很强的代码生成能力,可以根据自然语言描述生成代码,还具备代码补全、翻译和解释能力,以提高代码的效率和可读性。CodeGeeX目前拥有3.5万下载量。
aiXcoder:
2022年6月,AI编程机器人提供商aiXcoder推出了国内首个基于深度学习的智能编程模型——aiXcoder XL,该模型支持方法级的代码生成,可以根据自然语言描述生成完整程序代码。aiXcoder的研发人员主要来自北京大学,属于国内较早开启智能编程技术的研究与产业化应用的团队。
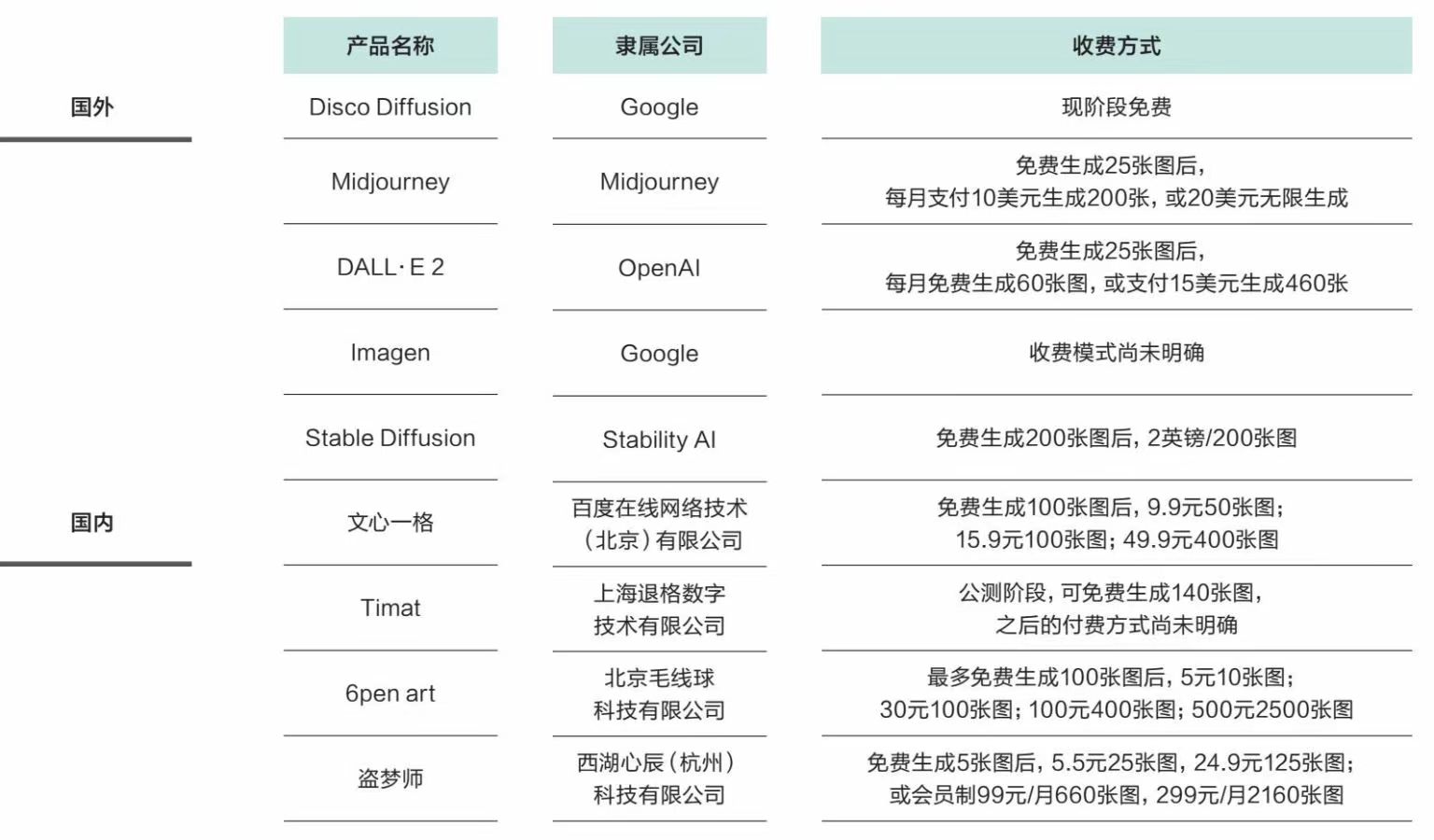
4、图片
5、视频
Gen-1:
生成式AI创业公司Runway今年2月发布的其首款AI视频编辑模型Gen-1,就可将现有的视频转换成另一种视觉风格。其原理其实和图片生成类似,Runway成立于2018年,曾参与AI绘画模型Stable Diffusion的开发。2023年3月20日,Runway也宣布将推出文生视频模型Gen-2,该模型能够根据文本描述生成三秒的视频,主要为创意人员和电影制作人提供帮助。
Make-A-Video:
2022年9月,Meta发布的AI视频生成工具Make-A-Video,除了在原始视频中加入额外的元素和变化,已经能做到依据文本,或单张/一对图片生成视频。
Imagen和Phenaki:
2022年,Google在一个月内也接连公布了Imagen和Phenaki两款AI生成视频的测试版,前者可以生成分辨率1280×768的高精度视频,还具有风格化和物体3D旋转能力,后者通过输入长达200多个字符的prompt,能创造2分钟以上的长视频,其技术突破重点在于探寻画面之间的逻辑,让AI具有讲故事的能力。
CogVideo:
清华大学曾联合智源研究院在2022年5月发布了首个开源的文本生成视频“CogVideo”模型。在其网站中,可以看到使用“一个男人在海边跑步”的文本生成的4秒视频,分辨率为480×480。
6、音频
MusicLM:
2023年1月底Google发布的最新AI模型MusicLM,只需要简单输入一段指令或图片,就可以生成对应的音乐,比如“在河边播放的冥想歌曲”、表达意境为“火”和“烟花”的音乐,它还能为音乐生成歌词以及续写音乐——上传一段乐器演奏、哼唱或是吹口哨的音频,MusicLM可以推断出额外的旋律小节,用户还可发布指令调节乐器的种类、演奏的力度等。事实上,MusicLM的“前身”AudioLM已经实现了音频的“预测”。
Jukebox:
OpenAI开发的“Jukebox”也具有类似功能,只不过,它似乎更强调风格。用户通过输入歌手、曲风等信息,就能生成一首相同风格的歌曲。同时,该模型可以通过学习现有的音乐,自动生成具有类似曲风的新片段。
Make-An-Audio:
浙江大学、北京大学联合火山语音,正在开发一款可以通过任意模态(文本、图像、视频、音频等)生成对应音频的系统Make-An-Audio,不过,它生成的不是音乐,而是音效。比如,当上传一幅闹钟图片,Make-An-Audio就能生成一段闹铃声。
#生成式AI #AI #人工智能